In the vast, uncharted ocean of human expression, where words ripple like waves and emotions surge like tides, lies a silent revolution—one that deciphers sentiment with the precision of a cartographer mapping uncharted territories. Welcome to the era of Advanced Sentiment AI, where Transformer architectures like BERT and RoBERTa don’t just read text—they understand it, dissect it, and distill its essence into actionable insights. These models are not mere algorithms; they are linguistic alchemists, transmuting raw words into emotional gold.
Imagine a world where every customer review, social media post, or support ticket becomes a whisper in a grand symphony of data. Sentiment AI listens, interprets, and harmonizes these whispers into a melody of meaning. But how? The answer lies in the intricate dance of Transformer architectures, where BERT and RoBERTa stand as titans, reshaping the landscape of natural language processing (NLP). Let’s embark on a journey through their neural labyrinths, where attention mechanisms are the compass and contextual understanding is the North Star.
The Genesis of Sentiment AI: From Bag-of-Words to Transformers
Once upon a time, sentiment analysis was a blunt instrument—a bag-of-words model that counted positive and negative terms like a child tallying marbles. It worked, but only as well as a sledgehammer in a watchmaker’s shop. The limitations were glaring: sarcasm was a foreign language, context was a ghost, and nuance? A distant dream.
Then came the Transformer revolution, a seismic shift in how machines process language. Introduced in the seminal paper Attention Is All You Need, Transformers ditched the sequential chains of RNNs and LSTMs, opting instead for a parallel, attention-driven architecture. This wasn’t just an upgrade—it was a paradigm shift. At its core, the Transformer relies on self-attention mechanisms, which allow it to weigh the importance of each word in a sentence relative to every other word. No longer did the model march word-by-word like a soldier in a parade; it now saw the entire sentence as a constellation, where each word’s position and relationship to others dictated its significance.
This was the birth of models like BERT (Bidirectional Encoder Representations from Transformers), which didn’t just read left-to-right or right-to-left but consumed the entire sentence at once, like a scholar poring over a manuscript with a magnifying glass and a philosopher’s intuition.
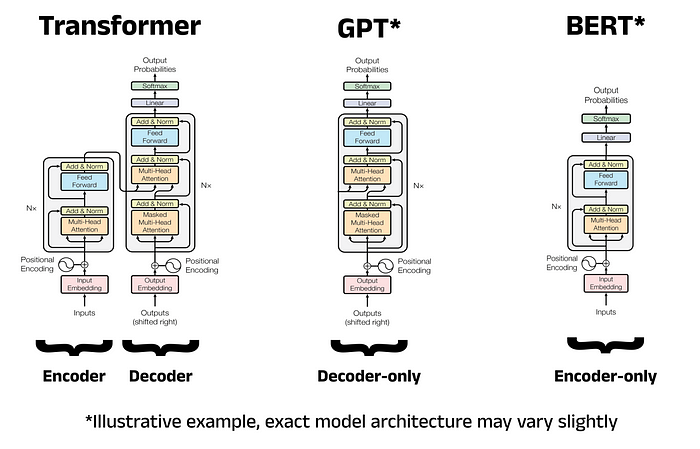
BERT: The Polymath of Language Understanding
BERT is the Renaissance man of NLP—a model so versatile it can dissect a Shakespearean sonnet, a Twitter rant, or a product review with equal aplomb. Its secret? Bidirectional context. Unlike its predecessors, which read text in one direction, BERT ingests the entire sentence simultaneously, allowing it to grasp the full tapestry of meaning. It’s as if BERT doesn’t just hear the words; it feels the emotions behind them.
But how does it achieve this linguistic clairvoyance? Through two ingenious pre-training tasks:
- Masked Language Modeling (MLM): BERT plays a game of linguistic hide-and-seek. It randomly masks 15% of the words in a sentence and trains itself to predict them. This forces the model to develop a deep, contextual understanding of language, where every word is a clue in a larger puzzle.
- Next Sentence Prediction (NSP): BERT is also a detective of coherence. It learns to determine whether two sentences logically follow each other, sharpening its ability to understand discourse and flow.
When fine-tuned for sentiment analysis, BERT doesn’t just classify text as positive or negative—it interprets the emotional subtext. A phrase like “This product is not bad” isn’t just neutral; BERT recognizes the subtle sarcasm, the undercurrent of disappointment masked by faint praise. It’s the difference between a thermometer and a seismograph—one measures temperature, the other detects tremors.
Yet, BERT isn’t without its quirks. Its hunger for computational resources is voracious, and its appetite for data is insatiable. Enter RoBERTa, the leaner, meaner sibling that refines BERT’s recipe with a dash of audacity.
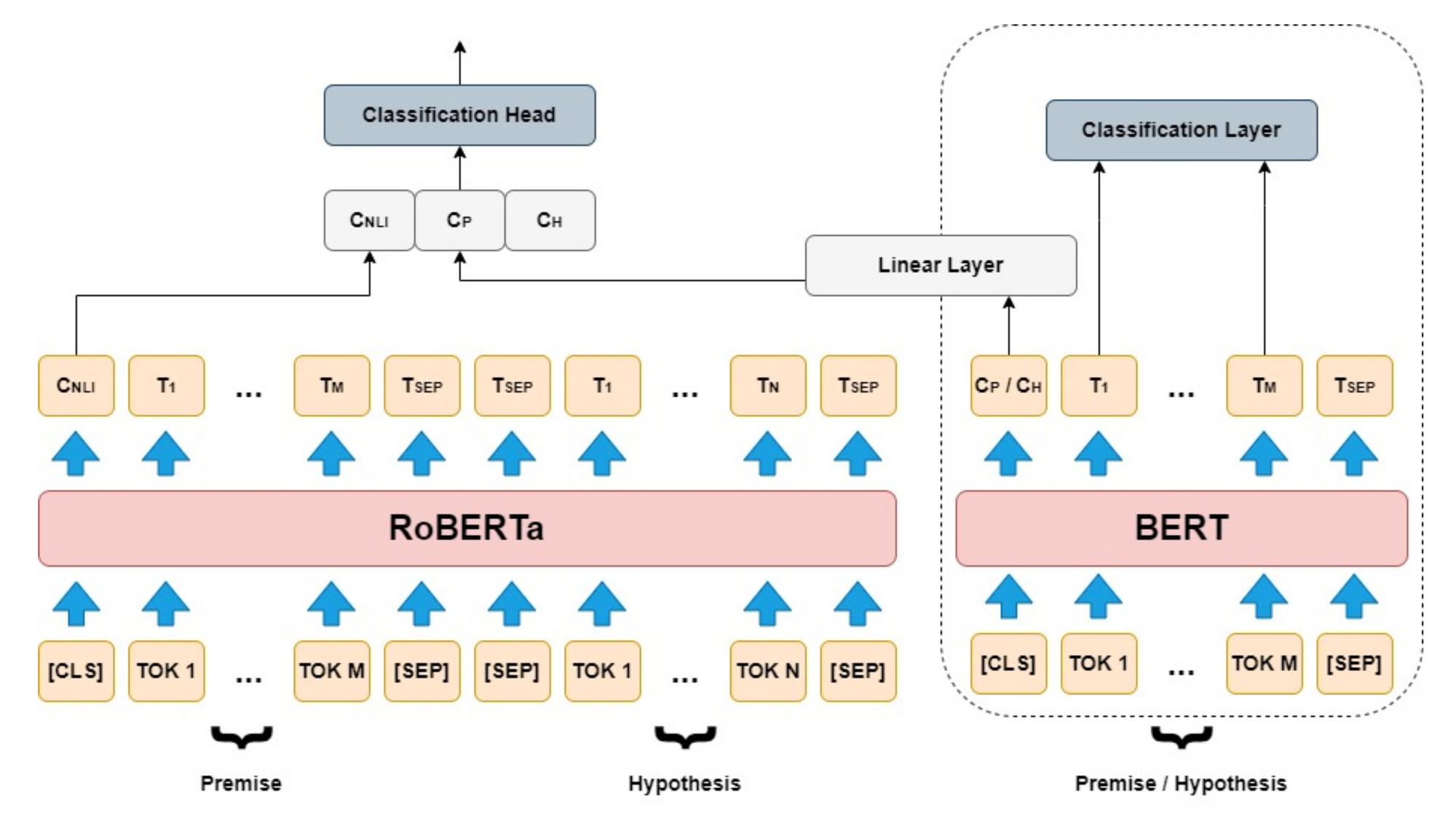
RoBERTa: The Ruthless Optimizer of Sentiment
If BERT is the scholar, RoBERTa is the athlete—built for speed, precision, and endurance. Developed by Facebook AI, RoBERTa (Robustly Optimized BERT Approach) takes BERT’s blueprint and cranks it up to eleven. It strips away the training wheels, eliminates the NSP task, and embraces a more aggressive pre-training regimen. The result? A model that’s faster, more accurate, and less prone to the pitfalls of overfitting.
RoBERTa’s improvements are subtle but transformative:
- Dynamic Masking: Unlike BERT’s static masking, RoBERTa regenerates the masked tokens for each epoch, ensuring the model isn’t lulled into complacency by repetitive patterns.
- Larger Batch Sizes: RoBERTa trains on bigger batches of data, allowing it to generalize better and avoid the myopia of small datasets.
- Longer Training: It doesn’t just sprint; it marathons. RoBERTa trains for more epochs, absorbing the nuances of language like a sponge in a downpour.
For sentiment analysis, RoBERTa’s robustness is a game-changer. It handles slang, emojis, and even typos with the grace of a linguist untangling a Gordian knot. A tweet like “@Company pls fix ur app ” isn’t just gibberish to RoBERTa—it’s a clear signal of frustration, punctuated by the urgency of a burning platform.
But here’s the kicker: RoBERTa doesn’t just outperform BERT in accuracy—it does so with fewer computational resources. It’s the difference between a V8 engine and a turbocharged four-cylinder: same destination, but with better fuel efficiency.
The Alchemy of Fine-Tuning: From Generalist to Sentiment Specialist
Pre-training is only half the battle. The real magic happens during fine-tuning, where BERT and RoBERTa shed their generalist personas and don the mantle of sentiment specialists. This is where the models transition from reading comprehension to emotional intelligence.
Fine-tuning involves training the model on a labeled dataset—thousands of sentences tagged with sentiment scores (e.g., 1 for positive, 0 for neutral, -1 for negative). The model learns to map text to these scores, but it’s not a simple lookup. It’s a dance of weights and biases, where the model refines its attention mechanisms to hone in on the most emotionally charged words and phrases.
Consider the sentence: “The customer service was as slow as molasses in January.” A bag-of-words model might stumble over the idiom, but BERT or RoBERTa recognizes the hyperbole, the frustration, and the underlying sentiment. It’s not just about the words; it’s about the weight of the words in context.
Fine-tuning also allows for domain adaptation. A sentiment model trained on movie reviews won’t necessarily excel at analyzing medical jargon. But with fine-tuning on domain-specific data, BERT and RoBERTa can become connoisseurs of their respective fields—whether it’s dissecting a Yelp review or a patient’s feedback in a clinical setting.
Beyond Binary: The Nuances of Sentiment Analysis
Sentiment isn’t a binary switch—it’s a spectrum. A review might be 70% positive but still bristle with 30% frustration. Traditional models crumble under this complexity, but BERT and RoBERTa thrive in the gray areas. They can output fine-grained sentiment scores, identifying not just the polarity (positive/negative) but the intensity and the underlying emotions (joy, anger, disappointment).
This granularity is invaluable for businesses. A customer service team doesn’t just need to know if a complaint is negative; they need to know how negative it is and why. Is the anger directed at a product flaw, a delayed shipment, or poor communication? RoBERTa can parse these subtleties, turning raw feedback into a roadmap for improvement.
Moreover, these models can detect emotional shifts within a single piece of text. A sentence like “The app is great, but the updates keep breaking things” isn’t just mixed sentiment—it’s a narrative arc of satisfaction followed by frustration. BERT and RoBERTa can capture this dynamism, providing a richer, more nuanced understanding of the user’s experience.
The Future: Sentiment AI as the Oracle of Human Experience
We’re standing on the precipice of a new era, where Sentiment AI isn’t just a tool—it’s a mirror. It reflects not just what people say, but how they feel, what they fear, and what they desire. BERT and RoBERTa are the first whispers of this revolution, but they won’t be the last.
Future advancements will likely focus on multimodal sentiment analysis, where text is just one layer of a richer, more complex data tapestry. Imagine a model that analyzes not just the words in a video review but the tone of voice, the facial expressions, and the body language of the speaker. This is the frontier where AI doesn’t just listen—it observes.
There’s also the tantalizing prospect of real-time sentiment analysis. In a world where social media moves at the speed of thought, models that can process and interpret sentiment in milliseconds will be indispensable. Picture a brand detecting a PR crisis as it unfolds, or a politician adjusting their rhetoric mid-speech based on the crowd’s emotional pulse.
Yet, with great power comes great responsibility. As Sentiment AI grows more sophisticated, so too do the ethical dilemmas. How do we ensure these models aren’t biased? How do we protect privacy in an age where emotions are data? These are the questions that will shape the next chapter of this journey.
The age of Advanced Sentiment AI is upon us. BERT and RoBERTa are not just tools; they are the harbingers of a future where machines don’t just understand language—they feel it. And in that future, the line between human and machine blurs, not in a dystopian haze, but in a symphony of shared understanding.
So the next time you type a review, post a tweet, or leave a comment, remember: somewhere, a Transformer is listening. Not just to your words, but to the emotions beneath them. And it’s learning. Always learning.
Leave a comment